Earlier today, some 19 hours ago at the time of writing, Eric Oakford opened an issue on the SCI Companion GitHub repo. Eric is working on a big decompilation project, taking mostly demo versions of SCI games and trying to wrangle them into a recompilable state.
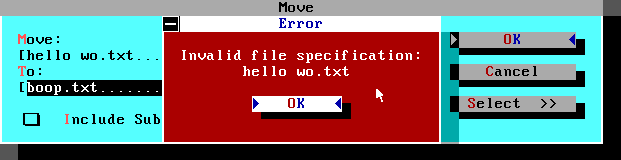
In the issue he’d opened, Eric described how the demo version of Leisure Suit Larry 3 didn’t decompile right, while the actual LSL3 worked fine. Here’s an example of the problem:
One of the first things a Room instance would normally do in its init method is to call (super init:), letting the Room class itself do its setup before anything specific to that room is done, like setting up actors, scripts, features, and walk polygons. In PMachine byte code that statement looks like this:
39 57 pushi 87 // the "init" selector
76 push0 // init takes no parameters
57 36 04 super Rm 4 // four bytes (two words) worth of stack to send
Now, the SCI PMachine is a stack machine, with two parts that are important to know about: the stack (because duh) and the accumulator. You can load numbers onto the accumulator, push them directly onto the stack, push the accumulator onto the stack, duplicate the top item, etcetera. Every value on that stack is a 16-bit number, as is the accumulator. Pointers? Just 16-bit numbers. Characters returned by StrAt? 16-bit numbers, even if it’s just ASCII codes. Properties and methods to invoke in a send? Yup.
There’s a separate table, vocabulary 997, that lists the name of every selector — every method and property of a class or instance. And that’s where it says that selector #87 is init.
Noting that super, self, and send are all three sides of the same weirdly-shaped coin, the decompiler can tell that there should be a (super ...) command in the output, four bytes of stack space back. Since it’s not actually running anything it has no actual stack, but it can look back to find two push operations that’ll fit the bill just as well. It can tell that the first value should be a selector, so whatever is being pushed is taken to be one, which is correct — 87 is the init selector. Then the next value is the amount of arguments given to init, which is zero.
But everything went wrong in the demo. This is how rm200, the overlook with the binoculars and memorial plaque, starts in the demo:
35 57 ldi 87
36 push
39 00 pushi 0
57 36 04 super Rm 4
The actual values on the stack stay the same — 87 0 — but the way they’re put on there is subtly different, and that tripped SCI Companion up.
Instead of (super init:), it decompiled the above as (super species?).
In fact, all selectors in code blocks were species. Six hours ago at the time of writing, I figured out the problem.
Now, the SCI Companion code is super hairy and I really couldn’t do it justice by just including snippets here but the gist of it?
Every operation may have a couple operands. One method in the decompiler returns what the first operand for a given operation in the byte code may be. For pushi, that’d be the immediate value to push. For push0, push1, and push2, that’d be zero, one, and two. For ldi it’s exactly the same as pushi, just that the operand is to be put in the accumulator, not the stack. By default, this method just assumes zero.
Notice how push has no operands at all? Why would it? It pushes the accumulator’s value, after all. The only difference between pushi 87 and ldi 87, push is that in the latter case, the accumulator is also 87. The accumulator doesn’t matter to a send, only the contents of the stack. And pushi 0 is just push0 with one extra byte. And that makes these two snippets effectively the same with regards to actual execution in an SCI interpreter.
So what happens when the decompiler sees the LSL3 demo’s scripts, is that it looks back for two pushes, as it should. It finds the first, push, which should be a selector. But the helper method that returns the value being pushed can’t return any operand — there are no operands here! So it returns the default, zero. Some confusion about it possibly being a variable later, it decides that it must be species. And then it does this for all the sends in the demo, because they all push their values the same way.
The fix came to me when I saw the case for the dup operation in that very same method that’s supposed to return the value that’d be pushed. It too takes no operands, yet does return a value that’s only zero if it should be. Turns out it scans back a bit, looking at the previous operation in the bytecode stream, and steals its value by calling the same helper method again, but aimed at the previous operation. The fix then is to make push also steal its predecessor’s value. I did decide to special-case things for now, though. It’ll only do the stealy thing if it’s an ldi–push pair, like in the LSL3 demo.
But it does work.
Addendum: You might wonder why the incorrect decompilation was (super species?) with a question mark instead of a colon. The decompiler and interpreter alike can tell which selectors on a given class are supposed to be properties, and which are methods. When invoking a method or setting a property, the standard is to use a colon, like in (theSong number: 4 play:), which is a property set followed by an arg-less method, and to use a question mark for property gets, like in (= theX (gEgo x?)). And since species is a property and there was no argument, it was taken to be a property get.

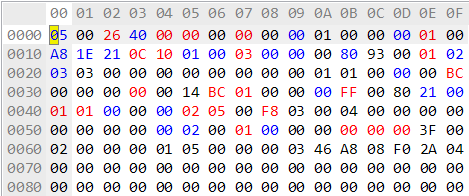
 If ROM-based games load so fast compared to disk-based games, why does Super Mario Bros 1 make you wait on a mostly-black screen before you get to play a given level? Why does Super Mario World? Surely it’s doing more than just sitting idly?
If ROM-based games load so fast compared to disk-based games, why does Super Mario Bros 1 make you wait on a mostly-black screen before you get to play a given level? Why does Super Mario World? Surely it’s doing more than just sitting idly? Now, the Super Mario Land games… they do what they want. SML1 for example subdivides levels into screens, which are lists of strips that can be reused at will. I think the screens themselves can also be reused. And that is then converted to a regular tile map. The original Legend of Zelda used a similar strip-based layout.
Now, the Super Mario Land games… they do what they want. SML1 for example subdivides levels into screens, which are lists of strips that can be reused at will. I think the screens themselves can also be reused. And that is then converted to a regular tile map. The original Legend of Zelda used a similar strip-based layout.